
J’utilise InfluxDB comme base de données pour stocker les informations de collectd et telegraf pour faire mon monitoring serveur (j’en avais écris un tutoriel) et j’avais alors à l’époque mis en place une rétention des données de 1 mois, sauf que… aujourd’hui je me rend compte que cette rétention ne semble pas être fonctionnelle !
Alors forcément les données de supervision ici ne sont pas lourdes, mais accumulées pendant 2 ans ça commence à peser quelques gigaoctets et c’est pas vraiment optimal, du coup dans cet article je vous explique comment mettre en place correctement une politique de rétention des données dans InfluxDB.
Sur votre terminal commencez par taper la commande « influx » pour ouvrir la CLI de InfluxDB.
Vous pouvez alors voir les politiques de rétention actuellement en place sur une base de donnée avec la commande suivante :
SHOW RETENTION POLICIES ON nom_base;Si vous ne vous souvenez plus du nom de votre base vous pouvez les lister la commande
SHOW DATABASESDans mon cas je me suis alors rendu compte qu’il y avait bien ma règle de 1 mois que j’avais mis en place à l’origine, mais qu’il y avait également encore la règle par défaut avec une rétention illimitée. Du coup faites bien attention ici à soit supprimer la politique par défaut et d’ensuite ajouter votre règle, soit de tout simplement modifier la règle par défaut ! Les commandes pour réaliser cela sont assez explicites :
- créer une politique de rétention de 1 mois :
CREATE RETENTION POLICY "nom_de_la_retention" ON "nom_base" DURATION 720h REPLICATION 1- modifier une politique de rétention en 24h :
ALTER RETENTION POLICY "nom_de_la_retention" ON "nom_base" DURATION 24h REPLICATION 1- supprimer une politique de rétention :
DROP RETENTION POLICY "nom_de_la_retention" ON "nom_base"Je vous invite tout de même à aller visiter la documentation pour vous l’approprier si vous souhaitez rendre certaines politiques par défaut ou si vous souhaitez gérer la réplication ou le sharding.
Attention une fois que vous aurez modifié ces politiques de rétention des données les changements ne sont pas instantanés et vous remarquerez peut-être que le poids de votre base ne change pas. On pourrait alors croire que les anciennes données ne sont pas purgées mais en fait encore une fois la documentation nous aide bien puisqu’elle explique que par défaut InfluxDB vérifie les politiques de rétention toutes les 30 minutes donc pas d’inquiétude il suffit d’être patient !
Si vous souhaitez modifier cette durée il suffit alors de modifier le fichier de configuration /etc/influxdb/influxdb.conf et de redémarrer influx :
[retention]
enabled = true
check-interval = "30m"Tout ça c’est rien de bien compliqué mais il y a quelques points d’attention à connaître et que je vous partage ici, au cas où ça pourrait servir 
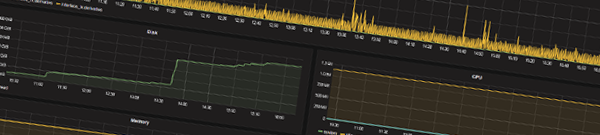
Parmis les nombreuses solutions de monitoring serveur je me suis penché il y a quelques mois sur une stack que j’utilise désormais : collectd + influxdb + grafana. Dans la suite de cet article je vous expliquerai l’utilité de chacune de ces briques, comment les installer et configurer, et bien entendu les lier ensemble pour obtenir un tableau de bord clair et précis de monitoring serveur.
Toutes les commandes ci-dessous ont été réalisées sous Debian 8 mais peuvent être adaptées pour la distribution de votre choix, les configurations des applicatifs entre eux ne devraient pas bouger.
1. Collectd
Collectd est un service Linux qui permet de collecter, transférer et sauvegarder des données de performance concernant un ordinateur et son équipement réseau.
C’est donc lui qui va récupérer toutes les données que l’on souhaite utiliser et visualiser graphiquement.
Son installation est simple :
sudo apt-get install collectdEnsuite il faut le configurer : modifier le fichier /etc/collectd/collectd.conf pour activer ou désactiver les plugins souhaités . Pour cela il suffit de commenter ou décommenter les lignes « LoadPlugin xxxxx ». Dans mon cas par exemple j’ai activé nginx, cpu, df, disk, memory, mysql, memcached.
Il est également nécessaire d’activer le plugin « network » puisqu’il permettra la communication entre collectd et influxdb. Ainsi dans ce même fichier /etc/collectd/collectd.conf il faut insérer les lignes suivantes pour indiquer que InfluxDB est sur la même machine et écoute sur le port 25826 :
<Plugin network>
Server "127.0.0.1" "25826"
</Plugin>De la même manière vous pouvez vous aider de la documentation de Collectd pour configurer les autres plugins dont vous avez besoin.
Il faut alors ensuite redémarrer collectd pour prendre en compte ces modifications :
sudo service collectd restart2. InfluxDB
InfluxDB est une base de données open source écrit en Go spécifiquement pour gérer des séries de données chronologiques. Ses points forts sont la haute disponibilité et la haute performance. C’est InfluxDB qui va sauvegarder les données de collectd pour ensuite être utilisées par Grafana.
Il est à noter que le fait qu’InfluxDB soit écrit en Go peut être une contrainte sur certains systèmes (compiler Go sur raspberry pi par exemple peut être très long).
Dans un premier temps il faut télécharger le package debian et l’installer :
wget https://s3.amazonaws.com/influxdb/influxdb_0.9.6_amd64.deb
sudo dpkg -i influxdb_0.9.6_amd64.debLa configuration se retrouve alors dans /etc/influxdb/influxdb.conf, il faut la modifier pour activer l’écoute de collectd :
[collectd]
enabled = true
bind-address = ":25826"
database = "collectd_db"
typesdb = "/usr/share/collectd/types.db"Par défaut une interface d’administration est activée sur le port 8083. Vous pouvez l’utiliser pour faire des tests et vérifier le bon fonctionnement de InfluxDB mais par sécurité je préfère la désactiver :
[admin]
enabled = false
bind-address = ":8083"
https-enabled = false
https-certificate = "/etc/ssl/influxdb.pem"
Il vous faut vérifier également que la configuration [http] est bien active sur le port 8086. Après redémarrage de InfluxDB (service influxdb restart) vous pouvez vous assurer du bon fonctionnement du service avec cette commande par exemple :
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=collectd_db" --data-urlencode "q=SELECT value FROM disk_read"Si vous recevez bien une réponse au format JSON avec des données alors c’est tout bon 
3. Grafana
Grafana est un « joli » tableau de bord permettant de visualiser différentes données via un navigateur web. Il est simple à utiliser, permet l’actualisation en temps réel ainsi que le déplacement dans le temps pour visualiser ses informations par dates (hier, aujourd’hui, les 6 dernières heures, etc).
3.1 Installation
Il est possible d’installer Grafana sous debian soit via package debian soit via dépôt APT (voir documentation). Je recommande fortement la version dépôt pour des questions de facilité et de maintenabilité :
- Ajouter la ligne suivante dans le fichier /etc/apt/sources.list :
deb https://packagecloud.io/grafana/stable/debian/ wheezy main(mettre exactement cette ligne même si vous êtes sur une version de debian ou de ubuntu différente)
- Ajouter la clé afin de pouvoir installer des package signés :
curl https://packagecloud.io/gpg.key | sudo apt-key add -- Mettre à jour les dépôts et installer Grafana :
sudo apt-get update
sudo apt-get install grafanaLa configuration de Grafana se trouve alors dans /etc/grafana/grafana.ini. Le service se lance alors sur le port 3000 avec la commande :
service grafana-server startIl reste alors à configurer Grafana : ajouter des sources, créer des requêtes pour mettre en place des graphiques de supervision.
3.2 Configuration
Il est nécessaire dans un premier temps de définir notre base de données collectd_db dans InfluxDB comme une source de données dans Grafana, remplissez alors le formulaire de création de la sorte :
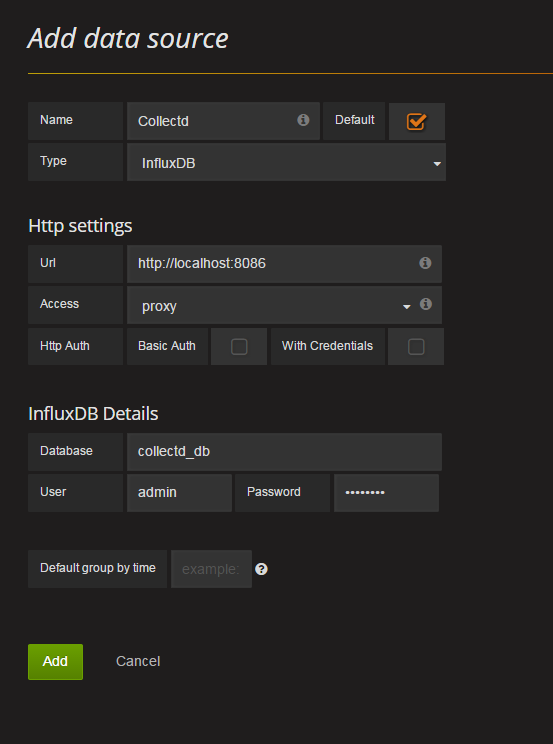
Ensuite vous pouvez alors créer votre premier tableau de bord (dashboard) qui contiendra des lignes dans lesquelles vous pourrez mettre en place des graphiques (ce qu’on appelle des requêtes) pour visualiser vos données.
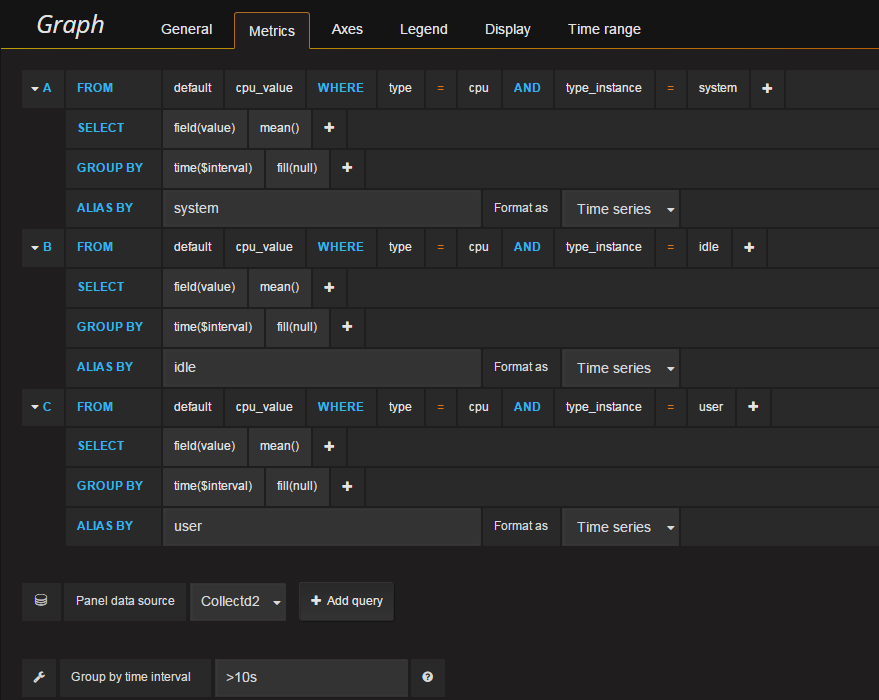
4. Exemples de requêtes
Vous trouverez ci-dessous des exemples de requêtes qui vous permettent de vous lancer dans vos premiers graphiques.
Sur chacune de vos requêtes pensez à mettre « Group by time interval » à >10s pour correspondre à la fréquence par défaut de Collectd.
De plus vérifiez bien à ce que votre « Panel data source » soit sélectionné sur votre base de données InfluxDB ajoutée précédemment comme data source de Grafana.
4.1 Disk

Penser dans l’onglet « Axes » de définir l’unité en « bytes » sur l’axe Y.
4.2 CPU
4.3 Memory

Attention : il faut bien penser dans l’onglet « Axes » de définir l’unité en « bytes » sur l’axe Y.
4.4 Network
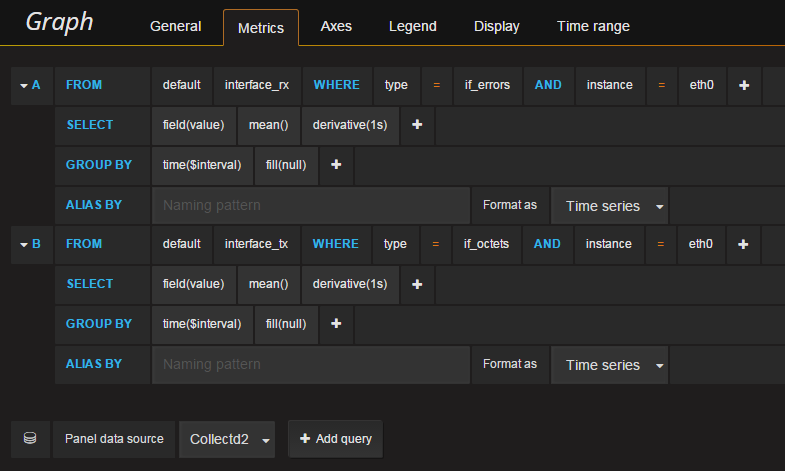
N’oubliez pas dans l’onglet « Axes » de modifier l’unité en bytes/sec sur l’axe Y.
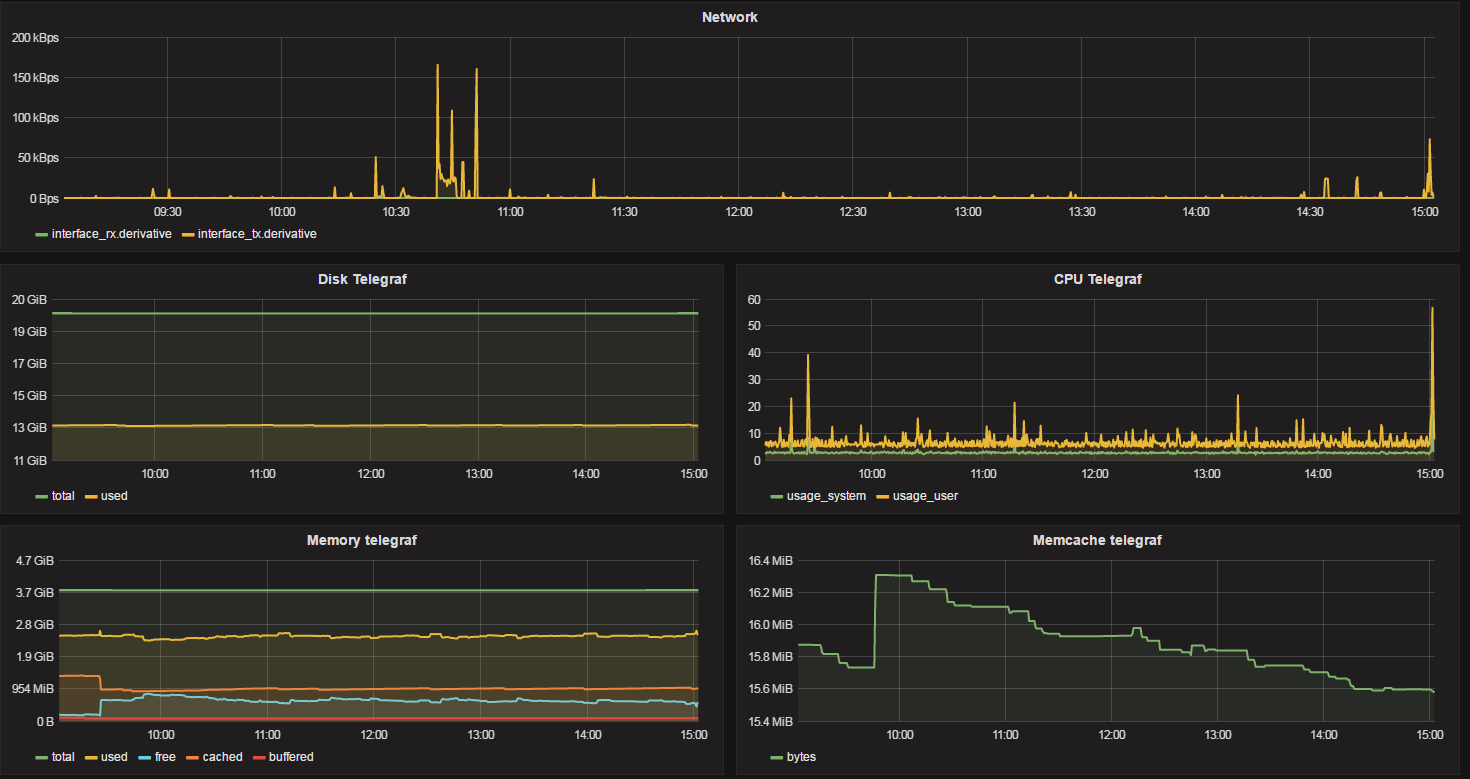
Et voilà, à vous de jouer maintenant ! Voici un bout de mon dashboard de supervision par exemple :

Si vous possédez un raspberry pi chez vous ou même une machine qui tourne sous Linux alors il se peut que vous souhaitiez pouvoir y accéder depuis internet plutôt que par le réseau local. Malheureusement vous n’avez peut-être pas une IP fixe fournie par votre FAI et pour cela il y a une solution : les DNS dynamiques. Bien qu’il existe de nombreuses plateformes proposant cela gratuitement, vous pouvez également utiliser un nom de domaine chez OVH puisque l’option « DynHost » est comprise dans leur offre.
1. Configuration OVH
La configuration de DynHost chez OVH est simple et se compose de plusieurs étapes :
- Se connecter à l’espace client
- Sélectionner son domaine (dans le menu de gauche)
- Cliquer sur l’onglet « DynHost »
- Cliquer sur « Gérer les accès » (bouton à droite)
- Créer un identifiant (bouton à droite)
- Créer un DynHost (bouton « Ajouter un DynHost » à droite)
- Saisir le nom de sous-domaine et y insérer une adresse IP (une adresse IP bidon suffit pour le moment)
Ces étapes sont documentées sur le site de OVH ici donc je ne vais pas les détailler plus que cela, mais je les ai répertorié ici pour que vous puissiez repérer les seules étapes nécessaires pour nous dans cette documentation.
2. Comment ça marche
Le script qui permettra de mettre à jour automatiquement votre adresse IP sur votre DynHost sera composé de X parties :
- on récupère l’adresse IP configurée sur le DynHost
- on récupère l’adresse IP courante
- on les compare
- on met à jour le DynHost s’il y a besoin
Pour récupérer l’adresse IP configurée actuellement sur le DynHost nous utiliserons la commande dig, si vous ne la possédez pas vous pouvez l’installer par exemple sur debian comme ceci :
sudo apt-get update
sudo apt-get install dnsutilsUne fois installé vous pouvez tester de récupérer cette adresse IP comme ceci :
dig +short votre.url.dynhostPour obtenir l’adresse IP courante nous utiliserons tout simplement la commande curl sur le site ifconfig.co, bien pratique pour notre cas :
curl ifconfig.coIl suffira alors de comparer les valeurs de ces deux commandes et si l’adresse IP enregistrée dans le DynHost est différente de l’adresse IP courante alors on mettra à jour le DynHost.
Il existe différentes méthodes pour mettre à jour le DynHost OVH : des packages debian, des scripts python, etc. Personnellement j’ai trouvé plus simple d’utiliser une bonne vieille commande curl sur le script OVH disponible avec les paramètres nécessaires :
curl --user "user:password" "https://www.ovh.com/nic/update?system=dyndns&hostname=votre.url.dynhost&myip=127.0.0.1"3. Script complet et CRON
Maintenant que vous avez compris comment cela fonctionnait, voici le script complet que j’ai réalisé :
#/bin/sh
#
# CONFIG
#
HOST=votre.url.dynhost
LOGIN=votre-login-dynhost
PASSWORD=votre-mot-de-passe
PATH_LOG=/var/log/dyndns
#
# GET IPs
#
HOST_IP=`dig +short $HOST`
CURRENT_IP=`curl ifconfig.co`
#
# LOG
#
echo > $PATH_LOG
echo "Run dyndns" >> $PATH_LOG
date >> $PATH_LOG
echo "Current IP" >> $PATH_LOG
echo "$CURRENT_IP" >> $PATH_LOG
echo "Host IP" >> $PATH_LOG
echo "$HOST_IP" >> $PATH_LOG
#
# DO THE WORK
#
if [ -z $CURRENT_IP ] || [ -z $HOST_IP ]
then
echo "No IP retrieved" >> $PATH_LOG
else
if [ "$HOST_IP" != "$CURRENT_IP" ]
then
echo "IP has changed" >> $PATH_LOG
RES=`curl --user "$LOGIN:$PASSWORD" "https://www.ovh.com/nic/update?system=dyndns&hostname=$HOST&myip=$CURRENT_IP"`
echo "Result request dynHost" >> $PATH_LOG
echo "$RES" >> $PATH_LOG
else
echo "IP has not changed" >> $PATH_LOG
fi
fi
Il vous suffit de modifier les lignes 7, 8 et 9 pour y mettre les paramètres qui correspondent à votre cas.
La ligne 11 peut également être modifiée pour définir le chemin d’accès aux logs de ce script.
Pour que ce script soit exécuté régulièrement, placez le dans le fichier /etc/cron.hourly/dyndns par exemple et exécutez ensuite la commande suivante :
sudo chmod +x /etc/cron.hourly/dyndnsEt voilà toutes les heures ce script s’exécutera et votre nom de domaine DynHost sera mis à jour s’il y a besoin.
Ce script est également disponible et maintenu sur mon GitHub.
The post DynHost OVH pour raspberry pi ou une machine linux first appeared on .]]>
Fin 2015 je suis passé de chez 1and1 en hébergement mutualisé à OVH en VPS (Virtual Private Server) pour la gestion de mes différents sites. Je me suis donc lancé sur leur offre VPS SSD et bien que j’en sois très satisfait je trouve qu’elle manque d’une chose importante pour tout admin système: les backups automatique. En effet cette fonctionnalité étant en option j’ai donc opté pour une solution « maison » permettant de mettre en place facilement l’automatisation de backups de sites, bases de données, configurations logicielles, etc. et de les sauvegarder dans n’importe quel cloud.
1. Création de backups journaliers
Dans un premier temps il faut archiver ses sites, pour cela rien de plus simple puisqu’il suffit de créer une tâche CRON journalière par site :
- touch /etc/daily.cron/backup
- chmod +x /etc/daily.cron/backup
- vim /etc/daily.cron/backup
Complétez et collez le code suivant :
#!/bin/sh
THESITE="NOM_DU_SITE"
THEDB="BDD_DU_SITE"
THEDBUSER="root"
THEDBPW="MDP_MYSQL"
THEDATE=`date +%d%m%y%H%M`
mysqldump -u $THEDBUSER -p${THEDBPW} $THEDB | gzip > /var/backups/files/dbbackup_${THEDB}_${THEDATE}.bak.gz
tar -czf /var/backups/files/sitebackup_${THESITE}_${THEDATE}.tar /var/www/vhost/$THESITE
gzip /var/backups/files/sitebackup_${THESITE}_${THEDATE}.tar
find /var/backups/files/site* -mtime +5 -exec rm {} \;
find /var/backups/files/db* -mtime +5 -exec rm {} \;
Dans les premières lignes on définit les paramètres nécessaires à l’archivage : nom du site, nom de la base de données, identifiants de connexion à MySQL.
Ligne 10 on exporte la base de données, puis dans les lignes 12-13 on créé l’archive des fichiers : vous devez également modifier le chemin vers le dossier de votre site par exemple.
Toutes les archives de backups sont donc stockées dans /var/backups/files, les archives vieilles de plus de 5 jours sont effacées pour éviter de prendre trop de place.
J’ai donc un fichier de ce type par site à sauvegarder, mais j’en ai également d’autres que j’ai adapté pour sauvegarder mes configurations nginx par exemple, à vous de décider ce que vous souhaitez sauvegarder
2. Installation de Rclone
Maintenant que les archives sont créées automatiquement, on va installer RClone : un programme en ligne de commande permettant de se connecter à de nombreux services de cloud (Google Drive, amazon S3, Dropbox, Amazon Cloud Drive, Microsoft One Drive, Hubic, etc.) afin de synchroniser des dossiers !
La démarche à suivre est simple :
- Récupérer l’url du fichier binaire de rclone adapté à votre distribution ici : http://rclone.org/downloads/
- Télécharger et installer le binaire sur votre plateforme
Ce qui donne par exemple :
wget http://downloads.rclone.org/rclone-v1.23-linux-amd64.zip
unzip rclone-v1.23-linux-amd64.zip
cd rclone-v1.23-linux-amd64
#copy binary file
sudo cp rclone /usr/sbin/
sudo chown root:root /usr/sbin/rclone
sudo chmod 755 /usr/sbin/rclone
#install manpage
sudo mkdir -p /usr/local/share/man/man1
sudo cp rclone.1 /usr/local/share/man/man1/
sudo mandb
rm rclone-v1.23-linux-amd64.zip3. Configurer Rclone avec Google Drive (ou le cloud de votre choix)
Maintenant que Rclone est installé, il faut le lier au service cloud de votre choix pour synchroniser vos archives. La documentation d’utilisation est détaillée pour chaque plateforme : par exemple pour utiliser Google Drive j’ai simplement suivi les instructions définies ici.
La démarche est plutôt simple, dans le cas d’un serveur distant il faut choisir « N » à l’option « Use auto config? » : Rclone va vous donner un lien à ouvrir dans votre navigateur afin de l’autoriser à accéder au service souhaité, ce dernier vous donnera alors une clé d’authentification qui sera à renseigner dans le prompt de votre invite de commande.
4. Utiliser Rclone pour synchroniser vos sauvegardes avec votre cloud
Désormais pour synchroniser le dossier « /var/backups/files » de votre serveur vers le dossier « vps_backup » de Google Drive par exemple il suffit d’utiliser la commande :
rclone sync local:/var/backups/files google_drive:vps_backupCette commande peut alors être utilisée dans une tâche CRON journalière pour que tout soit automatique